These are my notes for the seminars that happen in the Theory Group at The
University of Toronto. Many thanks to Professor Allan Borodin for allowing me to
attend the Theory Group seminars and helping out.
A PDF of these notes is available at https://rishit-dagli.github.io/cs-theory-notes/main.pdf.
An online version of these notes are available at https://rishit-dagli.github.io/cs-theory-notes.
The Theory Group focuses on theory of computation. The group is interested in
using mathematical techniques to understand the nature of computation and to
design and analyze algorithms for important and fundamental problems.
The members of the theory group are all interested, in one way or another, in the limitations of computation: What problems are not feasible to solve on a computer? How can the infeasibility of a problem be used to rigorously construct secure cryptographic protocols? What problems cannot be solved faster using more machines? What are the limits to how fast a particular problem can be solved or how much space is needed to solve it? How do randomness, parallelism, the operations that are allowed, and the need for fault tolerance or security affect this?
7th October 2022
The related paper: Combinatorial lower bounds for 3-query LDCs by Alrabiah et al. [1]. Seminar by Peter Manohar. [2] [3]
A code
is a q-locally decodable code (q-LDC) if one can recover any chosen bit
of the
-bit
message b with good confidence by randomly querying the
-bit encoding x on at most
coordinates. Existing
constructions of -LDCs
achieve blocklength ,
and lower bounds show that this is in fact tight. However, when
, far less is known: the
best constructions have ,
while the best known lower bounds, that have stood for nearly two decades, only show a quadratic
lower bound of
on the blocklength.
In this talk, we will survey a new approach to prove lower bounds for LDCs using recent advances in refuting semirandom instances of constraint satisfaction problems. These new tools yield, in the -query case, a near-cubic lower bound of , improving on prior work by a polynomial factor in .
Take codes
Codes are read by the decoder, ,
Ask the question, what is the best possible rate for a -LDC given a ?
| Lower Bound | Upper Bound | |
| 2 | ||
| 3 | ||
| , even | ||
| , odd | ||
Focus on the case , we have gotten better bounds:
| (1) |
In [1], they show that a better minimum bound can be found than these existing ones for :
| (2) |
The main result is that:
Semi-random CSP refutation comes to our aid to prove this! The intuitive way to put this theorem is that -LDC lower bound is same as refuting ”LDC” -XOR.
The idea:
-LDC lower bound is same as refuting ”LDC” -XOR
We can see that the decoder we have can arbitrary but WLOG we can assume there are -unif hypergraphs where every is such that:
We can also see that:
Each is a matching such that
and, picks
and
outputs
One such example is the Hadmard code:
| (3) |
Can think of this as
and
are connected.
Matching vector codes are
We suppose that our code is linear and that there exists
-unif
hypergraphs .
We also know that:
Each is a matching such that
and,
picks and
outputs
So, we start by considering a -XOR instance :
We can write down the maximum fraction of satisfiable constraints:
for
any .
It is sufficient now if we can argue that
is unsat with high
probability for some random
when .
Now we need to refute XOR, there are many ways to argue unsatisfiability of an
XOR instance. One reason why we can not use probablistic approaches here is that
only
has
bits of randomness.
One way we can have some success here is to use a refutation algorithm
With this the guarantee then would be
which is similar
to saying that if
then refutes
. The ideal goal would
be to refute random
with
constraints with high probability
However, we take a look at semi-random XOR. Our refutation algorithm and the guarantee will still be the same:
with the guarantee that .
So, now we generate semi-random constraints:
The equation we have is:
| (4) |
And we also already know that
And, .
is
almost semi-random.
Thus, we have shown 1 Part 1 of Proof.
-LDC XOR instance is encoded by:
We now have a goal to argue that
unsat with high probability for random when
when
frac. constraints satisfied by
is .
Here is:
| (5) |
This makes our goal to be to certify with high probability that:
| (6) |
We will now try to refute . With Equation 5 and Equation 6 to refute is like showing:
| (7) |
.
The idea is to design a matrix so that:
As shown by Wein et al. [4] the matrix can be indexed by
Assign such that
and
which is simply the tensor product.
We need to now be able to answer how to set
| (8) |
Which shows that we are actually using symmetric difference here.
We say that if then
if
| (9) |
Here
number of
where .
Simplifying an earlier statement we can also say from here that:
if
.
For which
and
Set
Note that the way we defined here it only depends on , we can say:
Also we know
and .
We have already proven that
It is also interesting to note that
and we still need to be able to show that with high probability that
is not
too large.
Matrix Bernstein: with high probability over
,
where
is the maximum number
of 1’s in a row in any .
Expected number of 1’s per row is .
We can optimistically suppose that
however this also needs .
Then
since
Now take
So,
Because are matchings, a
random row will have only
1’s.
The idea now is to prune off all the bad rows or columns in A to get B such that:
And,
And now we can just use instead which will prove -LDC lower bound for even.
Recall, -LDC XOR instance is encoded by:
The goal is argue that is unsatisfiable with high probability for random . And the idea is to design a matrix so that:
The previous approach fails because the
from before
requires
to be even.
One attempt is to represent rows as
and columns as . However
this will only get us to .
We need to derive more constraints, using
get us to
constraints
so each
is in
constraints
new
constraints.
The matrix is indexed by , . The calculation is now:
An optimist approach is
The row pruning tricks would still work provided that any is in at most constraints.
This proof for is not generalizable for all odd and neither is a reduction to -LDC. This is particularly true because of the row pruning step.
14th October 2022
The related paper: Algorithms for the ferromagnetic Potts model on expanders by Carlson et al. [5]. Seminar by Aditya Potukuchi.
The ferromagnetic Potts model is a canonical example of a Markov random field from statistical physics that is of great probabilistic and algorithmic interest. This is a distribution over all -colorings of the vertices of a graph where monochromatic edges are favored. The algorithmic problem of efficiently sampling approximately from this model is known to be #BIS-hard, and has seen a lot of recent interest. I will outline some recently developed algorithms for approximately sampling from the ferromagnetic Potts model on d-regular weakly expanding graphs. This is achieved by a significantly sharper analysis of standard ”polymer methods” using extremal graph theory and applications of Karger’s algorithm to count cuts that may be of independent interest. I will give an introduction to all the topics that are relevant to the results.
We start by defining some basic notation:
Notice that for
it means that we take the antiferromagnetic case. Here we talk more about when
meaning it is ferromagnetic.
This could have quite some applications:
we know
Now for it means that we
are doing a uniform -coloring
of
For we do a uniform
proper coloring of
What we need to do is given and , efficiently sample a coloring from this distribution.
| (10) |
We add the normalizing factor here:
Now we can also say,
| (11) |
A partition function of the model/distribution is very important for this
POV.
Our problem is that given and we want to efficiently sample a color distribution. We give 2 facts:
We now modify the problem as: Given
and ,
efficiently sample approximately a colouring from this distribution.
approximation will have us sample a law from such that , thus
| (12) |
We modify our original problem template to now be: Given
and
, efficiently sample
-approximately
a colouring from this distribution.
Fully Polynomial Almost Uniform Sampler can allow us to sample
-approximately
in
time.
Instead Fully Polynomial Time Approximation Scheme:
-factor
approximation in
time.
We can also show for a fact that .
The Antiferromagnetic Potts model:
| (13) |
where
Given and
, we want to be
able to give an FPAUS for this distribution. It is then equivalent to instead work on the problem:
given and
, give an FPTAS for
its partition function .
From some previous work, we know that there exists a such that:
We can say that this is #BIS-hard (bipartite independent sets). Thus, doing
this is at least as hard as an FPTAS for the number of independent sets in
bipartite graphs. If our graph has no bipartiteness then this becomes a NP-hard
problem.
For now, let’s consider the problem given a bipartite graph , design an FPTAS for the number of individual sets in . This accurately captures the difficulty of: the number of proper -colorings of a bipartite graph for , the number of stable matchings, the number of antichains in posets.
For our purposes we assume that is always a -regular graph on vertices. Now for a set , we define it’s edge boundary as:
Now, is an expander if for every of size at most , we have . For example we can take a discrete cube with vertices , is an edge if and differ in exactly 1 coordinate.
Using a simplification of the Harper’s Theorem we can say that
is a
-expander
[7].
Theorem 2. For each and there is a and such that there is an FPTAS for where is a -regular -expander providing the following conditions hold:
The main result shown was that
Theorem 3. For each , and large enough, there is an FPTAS for where for the class of -regular triangle-free -expander grpahs providing the following conditions hold:
This was previously known for:
Something to note here is that
should not be a necessary condition.
As well as as in the case does not require expansion or even that .
We first write the order-disorder threshold of the ferromagnetic Potts model
| (14) |
We want to be able to know more about how the Potts distribution looks for and for
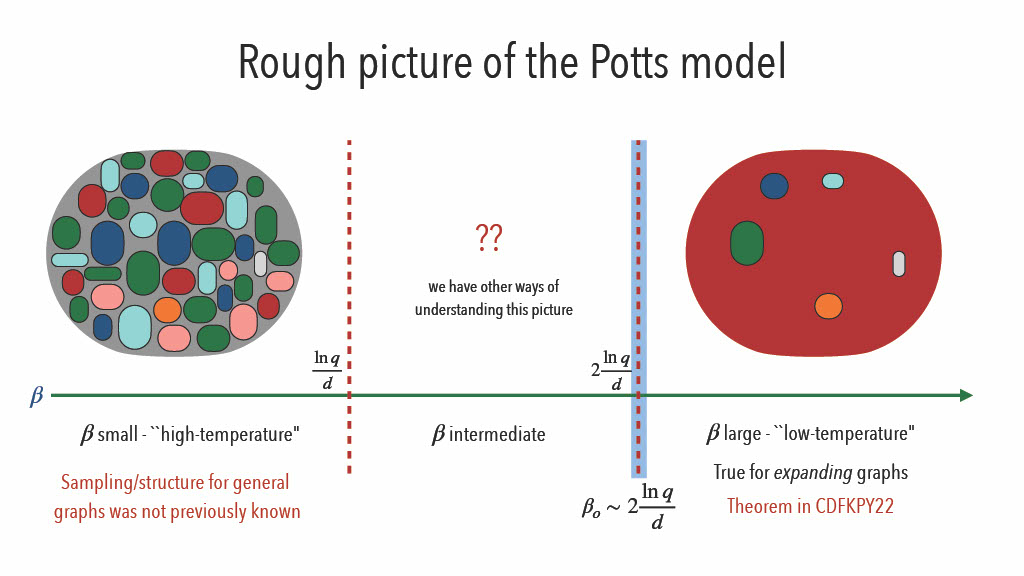
Another result we have is:
Theorem 4. For each , let be large enough , and be a -regular -expander graph on vertices then,
The strategy we have, to prove the theorem for :
The motivating idea is to visualize the state for
large
at low temperature as ground state + defects.
Typical Colouring = Ground State + Defects
Polymer methods are pretty useful in such cases. These were
first proposed in [8] and originated in statistical physics. We take
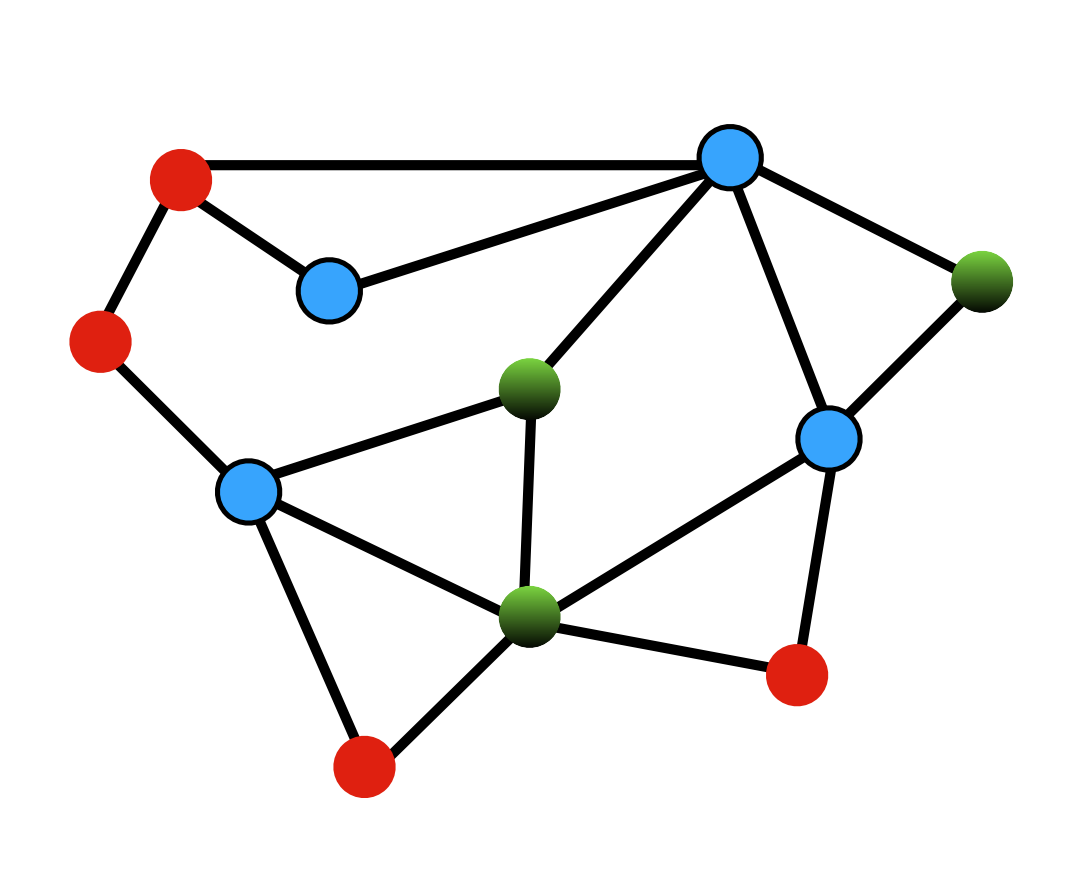
to be
our defect graph and each node in this represents a defect.
Now using Polymer methods
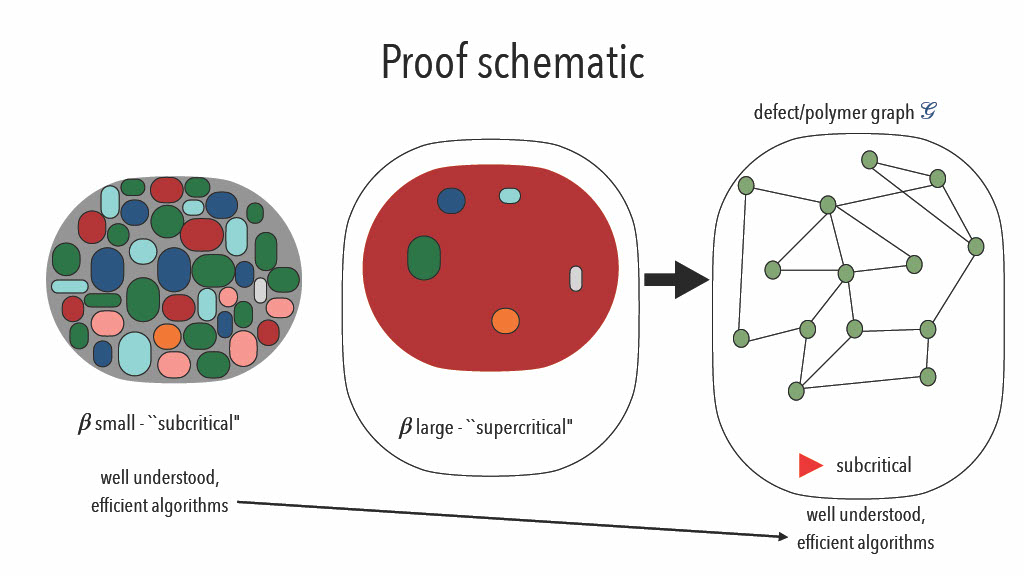
Ideas is to
where
where
is the weight
of polymer .
We now move towards cluster expansion: multivariate in the Taylor expansion of:
This is an infinite sum, so convergence is not guaranteed however convergence can be
established by verifying the Kotecký-Preiss criterion.
We also want to answer how many connected subsets are there of a given edge boundary in an -expander?
A heuristic we have is to count the number of such subsets that contain a given vertex
: a typical connected
subgraph of size is tree-like,
i.e., has edge boundary .
Working backward, a typically connected subgraph with edge boundary size has vertices. The number of such subgraphs number of connected subgraphs of size containing . The original number of subsets is also Number of rooted (at ) trees with vertices and maximum degree at most . Thus,
Theorem 5. At most connected subsets in an expander that contains have edge boundary of size at most .
Another question to ask is how many
-colorings of
an -expander
induce at most
non-monochromatic edges?
Easiest way is to make non-monochrimatic edges is to color all but randomly chosen vertices with the same color. Now, small these vertices likely form an independent set. we now color these vertices arbitrarily. There are:
ways.
Now we also know the maximum value of over all graphs with vertices, edges, and max degree . This will always be attained when is a disjoint union of and
18th October 2022
The related paper: Adversarially Robust Learning with Tolerance by Ashtiani et al. [9]. Seminar by Hassan Ashtiani.
Characterizing the sample complexity of different machine learning tasks is one of the central questions in statistical learning theory. For example, the classic Vapnik-Chervonenkis theory characterizes the sample complexity of binary classification. Despite this early progress, the sample complexity of many important learning tasks — including density estimation and learning under adversarial perturbations — are not yet resolved. In this talk, we review the less conventional approach of using compression schemes for proving sample complexity upper bounds, with specific applications in learning under adversarial perturbations and learning Gaussian mixture models.
We start by defining some notation:
Our goal is that for every ,
we want it to be
comparable to
with high probability.
We take the example of density estimation in this case . Now, probably approximately correct learns with samples if for all and for all with a . Now if then:
| (15) |
Now if we take the example of , let be the set of all Gaussians in then:
We will now modify the above equation. Now, probably approximately correct learns with samples if for all and for all . Now if then:
| (16) |
For the example of , let be the set of all Gaussians in then:
For the example of binary classification, we have
and
is some model
which maps from .
We also have and
then we will have the
be .
Now, probably approximately correct learns with samples if for all and for all . Now if then:
| (17) |
Now is the set of all half spaces in then:
For the example of binary classification, we have
and
is some model
which maps from .
We also have
adversarial pertubations and then we will have the
be
.
Now, probably approximately correct learns with samples if for all and for all . Now if then:
| (18) |
Now, consider the following and :
Here
is richer which can make it contain better models as well as harder
to learn. We can characterize the sample complexity of learning
using
Binary classification, with Binary classification with adversarial perturbations or with
Density estimation.
In the case of binary classification the VC-dimension quantifies complexity:
The upper bound here is achieved using simple ERM
And then for uniform convergence:
| (19) |
We now introduce sample compression as an alternative.
The idea is to try and answer how should we go about compressing a given training
set? In classic information theory, we would compress it into a few bits. In
the case of sample compression, we want to try to compress it into a few
samples.
If we just take the simple example of linear classification Number of required bits is
unbounded (depends on the sample).
It has already been shown by Littlestone and Warmuth [10] that Compressibility Learnability
It has also been shown by Moran and Yehudayoff [11] Compressibility Learnability
Sample Compression can be very helpful by:
Typical classifiers are often:
In the case of classification with adversarial perturbations we had
and
and then we will have the
be .
Now, probably approximately correct learns with samples if for all and for all . Now if then:
| (20) |
However one of the problems with this is if the robust ERM works for all
The robust ERM would not work for all , uniform convergence can fail,
can be unbounded.
We can say that any “proper learner” (outputs from
) can
fail.
In a compression-based method the decoder should recover the labels of the training set and their neighbors and then compress the inflates set:
So,
| (21) |
There is an exponential dependence on
.
Ashtiani et al. [9] introduced tolerant adversarial learning
PAC
learns
with
samples
if , , if then
| (22) |
And,
| (23) |
The trick is to avoid compressing an infinite set and now our new
goal is that the decoder should only recover labels of things in
.
To do so we can define a noisy empirical distribution (using
) and
then use boosting to achieve a super small error with respect to this distribution.
And then, we encode the classifier using the samples used to train weak learners and
the decoder smooths out the hypotheses.
It is interesting to think of Why do we need tolerance? There do exist some other ways to relax the problem and avoid
This is also observable in the density estimation example.
Gaussian mixture Models are very popular in practice and are one of the most basic universal density approximators. These are also the building blocks for more sophisticated density classes and can think of them as multi-modal versions of Gaussians.
We say is Gaussian
Mixture Model with
components in .
And we want to ask how many samples is needed to recover
within
error
.
The number of samples .
To learn single Gaussian in then
samples are sufficient (and necessary).
Now if we have Gaussian in then we want to know if
samples are sufficient?
There have been some results on learning Gaussian Mixture Models.
Let us take the example of this graph. For a moment look at this as a binary classification problem. The decision boundary has a simple quadratic form!
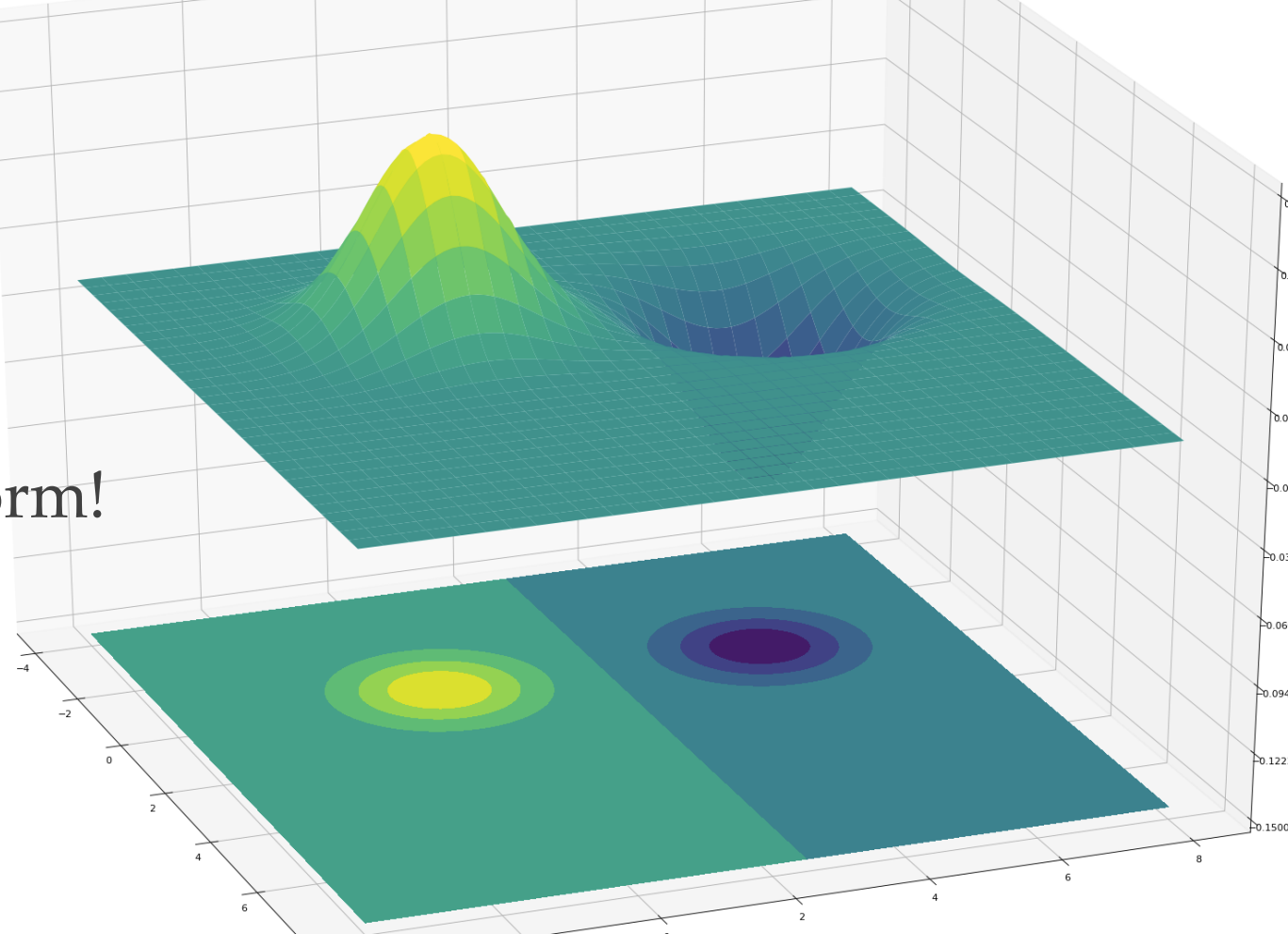
Here “Sample compression” does npt make sense as there are no “labels”.
We have which is a class of distributions (e.g. Gaussians) and we have. If A sends points from points and B approximates then we say admits -compression.
Theorem 7. If has a compression scheme of size then sample complexity of learning is
hides polylog factors.
Small compression schemes imply sample-efficient algorithms.
Distribution compression schemes extend to mixture classes automatically! So for the case
of GMMs in
it is enough to come up with a good compression scheme for a single Gaussian!
For learning mixtures of Gaussians, the encoding center and axes of ellipsoid is sufficient
to recover .
This admits
compression! The technical challenge is encoding the
eigenvectors
“accurately” using only
points.
can be large which is a technical challenge.
Compression relies heavily on a few points
Target compression is quite general
[1] Omar Alrabiah, Venkatesan Guruswami, Pravesh Kothari, and Peter Manohar. A near-cubic lower bound for 3-query locally decodable codes from semirandom CSP refutation. Technical Report TR22-101, Electronic Colloquium on Computational Complexity (ECCC), July 2022.
[2] Arnab Bhattacharyya, L. Sunil Chandran, and Suprovat Ghoshal. Combinatorial lower bounds for 3-query ldcs, 2019. URL https://arxiv.org/abs/1911.10698.
[3] Venkatesan Guruswami, Pravesh K. Kothari, and Peter Manohar. Algorithms and certificates for boolean csp refutation: ”smoothed is no harder than random”, 2021. URL https://arxiv.org/abs/2109.04415.
[4] Alexander S. Wein, Ahmed El Alaoui, and Cristopher Moore. The kikuchi hierarchy and tensor pca, 2019. URL https://arxiv.org/abs/1904.03858.
[5] Charlie Carlson, Ewan Davies, Nicolas Fraiman, Alexandra Kolla, Aditya Potukuchi, and Corrine Yap. Algorithms for the ferromagnetic potts model on expanders, 2022. URL https://arxiv.org/abs/2204.01923.
[6] Matthew Coulson, Ewan Davies, Alexandra Kolla, Viresh Patel, and Guus Regts. Statistical Physics Approaches to Unique Games. In Shubhangi Saraf, editor, 35th Computational Complexity Conference (CCC 2020), volume 169 of Leibniz International Proceedings in Informatics (LIPIcs), pages 13:1–13:27, Dagstuhl, Germany, 2020. Schloss Dagstuhl–Leibniz-Zentrum für Informatik. ISBN 978-3-95977-156-6. doi: 10.4230/LIPIcs.CCC.2020. 13. URL https://drops.dagstuhl.de/opus/volltexte/2020/12565.
[7] Peter Frankl and Zoltán Füredi. A short proof for a theorem of harper about hamming-spheres. Discrete Mathematics, 34(3):311–313, 1981.
[8] Tyler Helmuth, Will Perkins, and Guus Regts. Algorithmic pirogov-sinai theory. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019, page 1009–1020, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450367059. doi: 10.1145/3313276.3316305. URL https://doi.org/10.1145/3313276.3316305.
[9] Hassan Ashtiani, Vinayak Pathak, and Ruth Urner. Adversarially robust learning with tolerance, 2022. URL https://arxiv.org/abs/2203.00849.
[10] Nick Littlestone and Manfred Warmuth. Relating data compression and learnability. 1986.
[11] Shay Moran and Amir Yehudayoff. Sample compression schemes for vc classes. Journal of the ACM (JACM), 63(3):1–10, 2016.